Engineering the Singly Linked List
Posted by in Software Engineering on
The Linked List is one of the most important data structures available in a programmer's repertoire. Unfortunately, canned solutions are often either unsuitable for a particular application or even entirely unavailable within an environment or language. In these instances, it can be helpful to understand how to implement these structures. However, before the data structure can be implemented, it first needs to be defined and engineered. By the end of this entry, you should be able to describe and model a basic singly-linked list.
Engineering the Interface
In practice, a Linked List is used as a tool to accomplish a task rather than the desired end-goal of a project. This means that the structure could feasibly become an integral part of many separate parts of a program. It is important to take the time to establish the requirements and model the end-result before any code is written. This will be done in two steps: establish the features that the data structure must have, and define the interface by which external code will invoke those features. A good starting point for engineering is to list the features that an array would normally provide.
List Requirements
 The first requirement is that there must be a structure for the external code to interface with. Everything outside of the structure should be able to interact with the structure through that interface. This can be represented as a class (or an equivalent concept) in Object Oriented Languages.
The first requirement is that there must be a structure for the external code to interface with. Everything outside of the structure should be able to interact with the structure through that interface. This can be represented as a class (or an equivalent concept) in Object Oriented Languages.
The second requirement is that there must be a way to store information in the structure. External code should not be concerned with how this data is stored within the structure; but the interface by which code interacts with the list should be consistent across different list implementations. When data is stored in the structure, the structure must be able to insert the data at an arbitrary index if one is defined, or else to insert it at the end of the list.
The third requirement is that there must be a way to retrieve information from the structure. External code should be able to retrieve a value once it's stored. Since values are stored at indexes, then this means that external code must request data from a specific index.
The fourth requirement is that there must be a way to edit the values at existing indexes. The difference between an insertion and an edit is that editing overwrites a value at a specific index, while inserting should create a new value at an index without erasing any of the other values.
The fifth requirement is that there must be a way to remove values from the list. Again, since every value may be identified by an index, the external code must identify the index of the value to remove.
Finally, the sixth requirement is that there must be a way to determine the length of the list so that it may be iterated.
List Nodes

Once the outward-facing interface has been designed, the internal components need to be defined. The first problem that needs to be solved is to determine how data is stored within the structure. As discussed in Arrays, Linked Lists, and Dictionaries, a Linked List is a data structure that consists of serial nodes, where each node is accessible by one or more of its neighbors to form a chain, and where the data structure only tracks one or both ends of the chain. In a singly linked list, the chain may only be traced in one direction, while in a doubly linked list the chain may be traced in both directions.
Each node must be able to track a value, each node must be able to carry a value, and each node must be able to identify the next node in the chain. If there isn't another node, then a null value on that property could be used to indicate that it is the last node in the chain.
Engineering the Behavior
Once the interface has been defined, it's time to determine how the internal components of the structure functions. The first step is to define the behavior that each "public" function should perform. The second step is to see what functionality can be generalized from those public functions to containerize common functionality.
Insertions
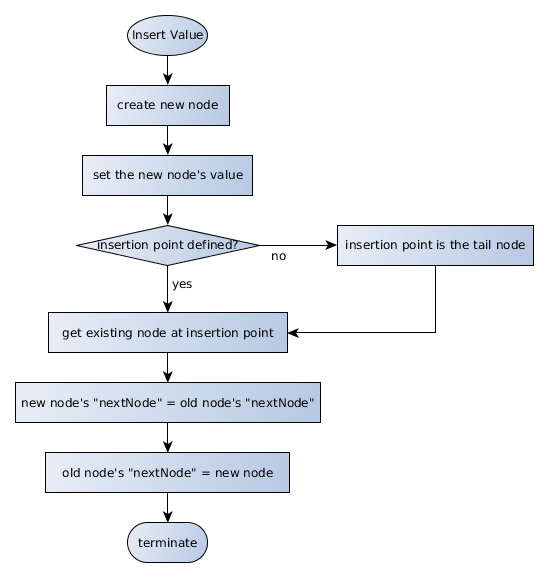
Insertions into the list should be able to either insert a value at a specific index, or have the value appended to the end of the structure if no index is defined. There are three places in the chain where a new value may be inserted: as the very first node in the chain, as the very last node in the chain, or somewhere between the first and last nodes.
- Inserting a value at the start of the chain should be a fairly straightforward task: create a new node, set its value, ensure that the "nextNode" value of the newly created node points to the chain's head, and then replace the chain's head with the newly created node.
- Inserting a value at the end of the chain should be a fairly straightforward task: create a new node, set its value, and update the "nextNode" value of the chain's tail so that it points to the newly created node.
- Inserting a value in the middle of the chain is slightly more complex: the node at the identified index would need to be referenced by the newly created node, and the preceding node would need to reference that newly created node.
A naive insertion algorithm is defined below. In production, the code should perform some error checking to validate that the insertion point is within reason — such as ensuring that the insertion point is not a negative number, and should define how the system would react if the insertion point were after the last index in the chain.
list.insert('my value');
list.insert('my other value', 0);Retrievals
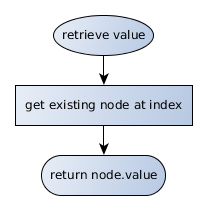
Retrieving values from the structure follows a similar pattern. Using the "get" function, external code should be able to retrieve values from any index within the structure, so long as that index is a valid integer.
When an index, n, is requested from the list structure, the list should fetch the "head" node and iterate through the chain until it reaches the nth node. Again, in production-ready code, some error-checking should be performed to ensure that n is a valid index; but a naive implementation will work for the prototype:
list.get(0);Updates
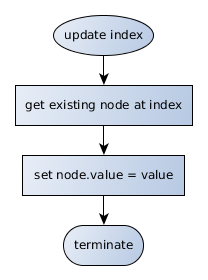
Updating a value also follows a very similar pattern to the previous two actions. Unlike retrievals, however, the "set" function should set the node's value instead of returning it:
list.set(0, 'my new value');Deletions
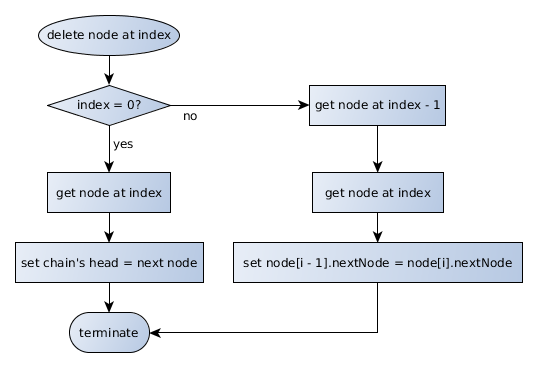
As with insertions, deletions must ensure that changes do not unintentionally disrupt the continuity of the chain. When removing a node from the system, the node must exist in one of three locations within the chain:
- The head of the chain, where there is no previous node but there may be trailing nodes. In this case, a deletion should set the "next" node as the new "head" of the chain.
- The tail of the chain, where there is no trailing node but there may be a previous node. In this case, a deletion should remove the "next node" reference from the previous node in the chain.
- Somewhere between the head and tail of the chain, where there is both a previous node and a trailing node. In this case, a deletion should set the "next node" reference in the previous node to equal the "next node" reference in the deleted node to ensure that the deletion only removes the required node.
list.remove(0);Chain Length
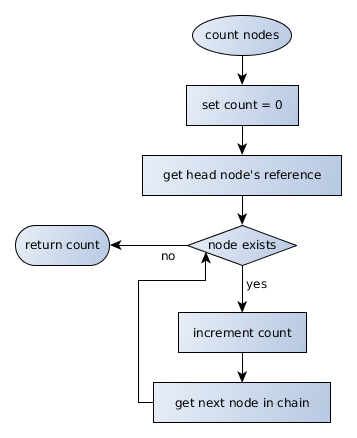
Finally, determining the list should be able to determine the length of the chain so that the chain may be iterated. The naive (and easy) way to handle this is to simply start at the "head" node, and iterate through the nodes to count them. Once the nodes have been counted, then the chain length can be returned as an integer value that is greater than or equal to zero (≥ 0). If the length is 0, then there are no indexes; if the length is greater than zero, then it may be iterated with a standard "for" loop:
for (i = 0; i < list.count(); ++i) {
list.get(i);
}Generalizing Behavior

Now that the behavior has been planned, repeated patterns can become opportunities for generalized behavior within the class. These patterns, when recognized, may be implemented as functions to reduce the amount of duplicate code in the structure. This will lead to more intuitive code that is easier to read, and it helps to ensure that related behaviors within the structure yield consistent and predictable results.
The most common action taken within the structure is the retrieval of a node at a specific index. Generalizing this function would support the insert, get, set, and delete functions because they all rely on the ability to fetch an indexed node from the chain. This would also help to centralize the index-related error-checking, since most of the index-related code would be located within one function.
Summary
By engineering the project ahead of time, the public interface can be defined before any code is written. This allows other code to be written around the assumption that the interface will behave in a certain way, but also allows the developer flexibility to replace or improve that functionality later. Although no code has been written to create this data structure, the existence of these diagrams do not bind a developer to a particular implementation; and the structure could be implemented in any language that supports the Object Oriented paradigm.
Related Blog Posts



